L’intelligence artificielle s’est imposée ces dernières années comme un levier incontournable de transformation. Désormais omniprésente dans notre quotidien, elle prend des formes variées : machine learning, modèles de langage (LLM), IA générative, chatbots, etc. Les IA génératives, en particulier, ont connu une croissance fulgurante et s’invitent désormais dans notre quotidien comme dans nos pratiques professionnelles. Après l’ère de la digitalisation et de la transformation numérique, nous entrons dans une nouvelle phase où l’IA redéfinit nos pratiques, accélère l’innovation et reconfigure les dynamiques de performance. Dans cette course à la compétitivité, intégrer des solutions d’IA devient un enjeu stratégique majeur pour améliorer productivité, agilité et prise de décision.
Dans le domaine du Knowledge Management (KM), l’IA fait une entrée remarquée. Elle offre aux organisations de nouvelles opportunités pour repenser la circulation, l’exploitation et la valorisation des connaissances. Véritable catalyseur pour les systèmes de gestion des connaissances, l’IA devient un pilier central de leur évolution. Dans cet article, nous verrons comment l’IA transforme le Knowledge Management, en identifiant à la fois ses apports, ses limites et les défis associés. Nous soulignerons également en quoi une démarche KM solide peut renforcer l’efficacité et la fiabilité des outils d’IA.

L’Intelligence Artificielle (IA) désigne un ensemble de théories et de techniques visant à développer des systèmes capables de reproduire certaines capacités cognitives humaines. En imitant le raisonnement, la résolution de problèmes, la reconnaissance de schémas, ou encore la compréhension du langage naturel, les algorithmes d’IA peuvent réaliser des tâches traditionnellement réservées à l’humain. Les applications sont nombreuses, allant de missions ciblées comme la gestion des stocks, à des usages plus complexes, comme le traitement conversationnel incarné par des outils tels que ChatGPT.
Pour mieux comprendre le fonctionnement de l’IA, il est essentiel de distinguer les différents modèles de traitement de données qui la composent, notamment ceux liés au langage humain :
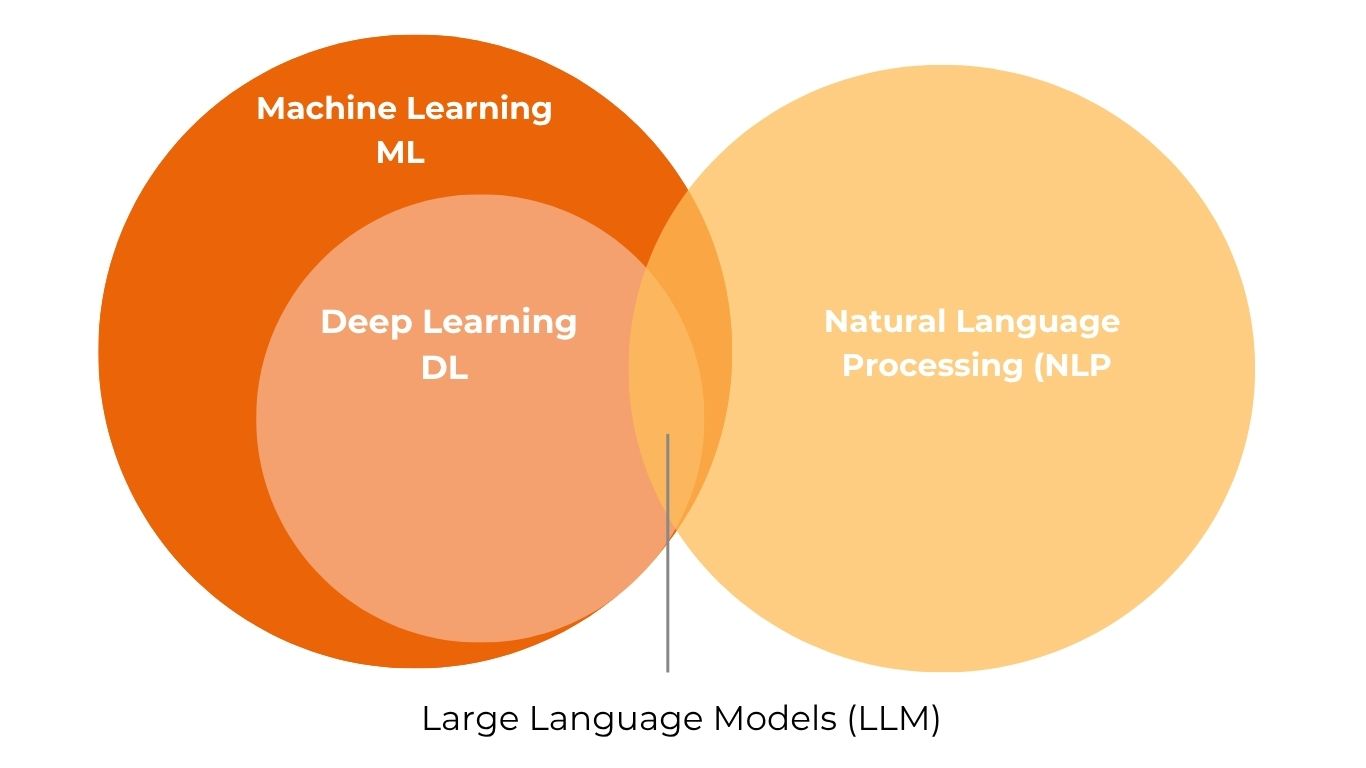
Bien que l’IA soit aujourd’hui omniprésente, il reste souvent difficile de distinguer clairement les différents modèles, leurs mécanismes et leurs domaines d’application respectifs. Parmi les nombreuses catégories, les IA génératives occupent une place à part : elles regroupent l’ensemble des technologies capables de produire du contenu à partir de données qu’il s’agisse de texte, d’images, de son, de code ou encore de vidéos. À l’intérieur de cette famille, les Large Language Models (LLM) représentent une catégorie spécifique, centrée sur le traitement du langage naturel. Ils comptent parmi les formes d’IA générative les plus répandues, avec des outils emblématiques tels que ChatGPT, Gemini ou encore Claude.
Depuis quelques années, les technologies d’intelligence artificielle se déploient massivement dans l’ensemble des secteurs industriels. Elles sont notamment utilisées dans la production grâce à la robotique, mais aussi dans des processus tels que le contrôle qualité (via la reconnaissance de défauts et non-conformités), la maintenance prédictive, ou encore l’automatisation et l’optimisation de tâches ne nécessitant pas d’intervention humaine directe. L’IA est également présente tout au long de la chaîne d’approvisionnement, en particulier pour anticiper les besoins et optimiser la gestion des stocks.
Une application plus récente de l’IA concerne la gestion des connaissances. De nombreuses entreprises cherchent aujourd’hui à renforcer les performances de leurs outils internes, comme les moteurs de recherche ou les bases documentaires, en y intégrant des agents conversationnels (chatbots). Ces derniers sont capables de répondre aux questions des utilisateurs, de résoudre des problèmes simples ou encore de générer et mettre à jour automatiquement du contenu existant.
Dans tous ces cas, les solutions reposent sur des réseaux de neurones artificiels, dont la performance dépend directement de la qualité des données utilisées : des données structurées, validées et nettoyées sont indispensables pour garantir des résultats fiables. Ce besoin de données maîtrisées constitue un dénominateur commun entre les différentes applications industrielles de l’IA.
Ces similitudes permettent d’en tirer des enseignements utiles pour l’application des LLM à la gestion des connaissances, en identifiant à la fois les apports potentiels de ces technologies et les limites à anticiper dans une stratégie de Knowledge Management.
Avant de rappeler les apports et les limites de l’IA, il est essentiel de rappeler l’un des enjeux majeurs du Knowledge Management. En effet, face à l’explosion des volumes d’informations et de données critiques, la gestion des connaissances s’impose aujourd’hui comme un levier stratégique pour la performance des organisations. Malgré l’utilisation d’environnements collaboratifs structurés (comme ceux proposés par Google, Microsoft, etc.), la capitalisation et la valorisation de l’expertise restent des défis complexes à relever.
Le phénomène est accentué par l’augmentation constante des bases de données : leur volume double chaque année. À titre d’exemple, un grand constructeur automobile français gère à lui seul près de 140 000 bases de données, illustrant l’ampleur du défi. Cette complexité a un impact direct sur la productivité des équipes, qui consacrent en moyenne plus de deux heures par jour à rechercher l’information pertinente pour mener à bien leurs missions.
Une statistique révélatrice souligne l’inefficacité actuelle des systèmes de gestion documentaire : huit collaborateurs sur dix déclarent recréer des documents déjà existants, faute de les avoir retrouvés dans les bases disponibles. Cela illustre l’urgence d’optimiser la circulation, l’accès et la valorisation de la connaissance au sein des organisations. Ainsi l’accès rapide et pertinent à l’information est un enjeu crucial de productivité. Aujourd’hui, l’un des moyens les plus efficaces pour obtenir une réponse fiable et contextualisée reste de solliciter directement un expert. Cette approche permet non seulement d’obtenir une réponse précise, mais aussi de bénéficier d’éléments essentiels à la compréhension tels que l’historique du projet, le contexte opérationnel ou encore les enjeux sous-jacents. Cependant, cette méthode présente plusieurs limites : identifier le bon interlocuteur, s’assurer de sa disponibilité, voire de sa présence encore effective dans l’entreprise peut s’avérer complexe. D’où l’importance stratégique de capturer, structurer et formaliser l’expertise tant qu’elle est accessible, afin d’en garantir la traçabilité, la réutilisabilité et la pérennité au sein de l’organisation.
Intégrer l’IA apporte plusieurs avantages clés en faveur d’une stratégie de gestion des connaissances performante en répondant à des enjeux stratégiques tels que :
Comme évoqué précédemment, malgré les bénéfices indéniables des technologies d’Intelligence Artificielle, leur intégration soulève également un certain nombre de limites à considérer attentivement. Ces freins, particulièrement visibles dans le cas des Large Language Models (LLM), peuvent impacter la fiabilité, l’efficacité et la sécurité des dispositifs de structuration et de valorisation du patrimoine technique des entreprises.
Principales limites identifiées :
Nous disposons toutefois de leviers éprouvés pour dépasser efficacement ces limites. L’alliance entre les outils d’Intelligence Artificielle et une démarche de Knowledge Management structurée et performante constitue un facteur clé de réussite. En s’appuyant sur des bases de connaissances bien organisées et des processus solides, il devient possible de renforcer durablement la gestion des savoirs et le transfert d’expertise au sein des organisations.
L’Intelligence Artificielle représente donc un levier prometteur pour renforcer les démarches de gestion des connaissances, mais elle comporte également des risques qu’il convient d’anticiper. La complexité des algorithmes rend leur maîtrise difficile en pratique ; c’est précisément ici que le Knowledge Management (KM) trouve tout son sens. Il agit en amont, sur les causes et les symptômes, pour structurer un système de gestion des connaissances fiable et performant.
La plupart des limites associées à l’IA, telles que le manque de contextualisation, les biais ou les résultats erronés, sont souvent liées à la façon dont les connaissances internes sont organisées et valorisées. La forte dépendance de l’IA à la qualité des données doit ainsi être perçue comme une opportunité : celle de structurer des bases de connaissances robustes, complètes et alignées avec les exigences métiers. Il est donc essentiel de capturer efficacement les savoirs clés, de les organiser de manière logique et de garantir la fiabilité des contenus exploités.
Pour faire face à cet enjeu, la mise en œuvre d’une véritable démarche de conduite du changement est indispensable. Celle-ci implique l’instauration de nouvelles habitudes au sein des équipes, notamment avec l’aide d’une solution dédiée à la gestion des connaissances. Cette solution joue le rôle de filet de sécurité, en s’assurant de la pertinence des données mises à disposition des IA, et donc de la qualité des réponses produites. Elle permet ainsi aux utilisateurs d’interagir en toute confiance avec ces technologies.
Dans ce contexte, un principe bien connu du domaine de l’IA résume parfaitement l’enjeu : « Garbage In – Garbage Out ». Autrement dit, il est illusoire d’attendre des résultats fiables de la part d’une IA si les données entrées sont de mauvaise qualité, un rappel fondamental pour toute organisation souhaitant tirer pleinement parti de l’Intelligence Artificielle.

Ainsi, une démarche rigoureuse de Knowledge Management en amont est indispensable pour garantir des données fiables, cohérentes et exploitables durablement. Dans ce contexte, les rôles s’inversent : ce n’est plus seulement l’IA qui soutient la gestion des connaissances, mais bien une gestion des connaissances maîtrisée qui devient un levier stratégique pour optimiser les performances des outils d’intelligence artificielle.
Pour constituer une base de données pertinente, plusieurs critères essentiels doivent être respectés :
Le traitement de l’ensemble de ces critères peut rapidement devenir complexe et particulièrement chronophage, notamment en raison de l’ampleur et du volume des données à traiter. C’est pourquoi il est vivement recommandé de s’appuyer sur l’expertise de professionnels du Knowledge Management. Leur accompagnement permet de sécuriser chaque étape de la démarche : de l’identification des savoirs clés à leur structuration, jusqu’à leur capitalisation dans une base de connaissances solide, hébergée sur une plateforme digitale fiable et pérenne.
Par ailleurs, le recours à un accompagnement externe par des experts, ainsi que l’appui d’un logiciel spécialisé, constitue un véritable atout dans la réussite de la démarche. Le traitement de l’expertise est en effet un sujet particulièrement délicat, en raison de la diversité des types de connaissances à prendre en compte :
Face à cette complexité, la mise en œuvre d’une démarche efficace implique un travail préparatoire minutieux d’identification, de qualification et de structuration de ces différentes formes de connaissance, afin de les rendre accessibles, mobilisables et valorisables à l’échelle de l’organisation.
L’un des freins majeurs à l’adoption de l’intelligence artificielle dans l’industrie, en particulier dans des contextes sensibles ou réglementés, réside dans les risques d’hallucinations. Une gestion rigoureuse des connaissances peut contribuer à limiter ces risques et favoriser un usage plus maîtrisé de l’IA.
Plusieurs leviers peuvent être actionnés à cet effet :
Le déficit de bon sens et de compréhension fine du contexte par l’IA constitue un symptôme important à ne pas négliger. Le traiter efficacement peut devenir un véritable avantage concurrentiel. Il reflète directement la capacité d’une organisation à capitaliser et à diffuser ses connaissances de manière pertinente.
En effet, si l’IA permet souvent de générer des réponses rapides, elle ne favorise pas toujours l’apprentissage en profondeur, pourtant essentiel pour anticiper les projets, mobiliser l’expérience passée, assurer la reproductibilité des bonnes pratiques et s’adapter aux spécificités du terrain.
C’est pourquoi la combinaison de l’IA avec des approches plus traditionnelles de gestion des connaissances, comme l’exploitation des retours d’expérience (REX), constitue une méthode clé pour renforcer la performance globale et stimuler l’innovation.
L’un des secrets d’un usage optimal de l’IA réside dans une approche hybride : ne pas se reposer sur un seul outil ou une seule solution, mais intégrer intelligemment différents dispositifs et méthodologies. Cette complémentarité permet d’optimiser l’efficacité de l’IA et sa pertinence, quel que soit le contexte d’application.
Dans un environnement industriel en constante évolution, où la complexité des enjeux techniques, humains et organisationnels est croissante, l’intelligence artificielle représente un outil prometteur pour gagner en efficacité, en réactivité et en compétitivité. Toutefois, ses limites notamment en matière de compréhension fine du contexte, de raisonnement critique ou encore d’interprétation du non-dit imposent une approche plus globale.
C’est donc en l’associant aux outils et aux pratiques de gestion des connaissances (KM) que l’IA peut pleinement révéler son potentiel et générer une vraie valeur. En effet, les dispositifs KM comme les retours d’expérience (REX), les bases documentaires métier, les communautés de pratique ou encore les processus de capitalisation permettent de structurer, fiabiliser et contextualiser les savoirs. Combinés à l’IA, ils facilitent la résolution collaborative des problèmes, améliorent la qualité des décisions et renforcent la transmission intergénérationnelle des expertises.
Pour les industriels, cette hybridation entre IA et KM constitue une voie stratégique : elle ne repose pas uniquement sur la performance des outils, mais sur la capacité à faire travailler ensemble les technologies, les processus et les hommes. Le véritable levier de différenciation ne se trouve donc pas dans l’IA seule, mais dans la manière dont elle est intégrée à un écosystème de connaissances vivantes et partagées.